RDF、RDFS、OWL
RDF
Example3 Turtle:
@prefix person: http://www.kg.com/person/ .
@prefix place: http://www.kg.com/place/ .
@prefix : http://www.kg.com/ontology/ .
person:1 :chineseName “罗纳尔多·路易斯·纳萨里奥·德·利马”^^string;
:career “足球运动员”^^string;
:fullName “Ronaldo Luís Nazário de Lima”^^string;
:birthDate “1976-09-18”^^date;
:height “180”^^int;
:weight “98”^^int;
:nationality “巴西”^^string;
:hasBirthPlace place:10086.
place:10086 :address “里约热内卢”^^string;
:coordinate “-22.908333, -43.196389”^^string.
即,将一个实体用一个句子表示(这里的句子指的是一个英文句号“.”)而不是多个句子,属性间用分号隔开。
RDF的表达能力有限,无法区分类和对象,也无法定义和描述类的关系/属性。我的理解是,RDF是对具体事物的描述,缺乏抽象能力,无法对同一个类别的事物进行定义和描述。就以罗纳尔多这个知识图为例,RDF能够表达罗纳尔多和里约热内卢这两个实体具有哪些属性,以及它们之间的关系。但如果我们想定义罗纳尔多是人,里约热内卢是地点,并且人具有哪些属性,地点具有哪些属性,人和地点之间存在哪些关系,这个时候RDF就表示无能为力了。
RDFS和OWL这两种技术或者说模式语言/本体语言(schema/ontology language)解决了RDF表达能力有限的困境。
RDFS
RDFS/OWL本质上是一些预定义词汇(vocabulary)构成的集合,用于对RDF进行类似的类定义及其属性的定义。
我们这里只介绍RDFS几个比较重要,常用的词汇:
- rdfs:Class. 用于定义类。
- rdfs:domain. 用于表示该属性属于哪个类别。
- rdfs:range. 用于描述该属性的取值类型。
- rdfs:subClassOf. 用于描述该类的父类。比如,我们可以定义一个运动员类,声明该类是人的子类。
- rdfs:subProperty. 用于描述该属性的父属性。比如,我们可以定义一个名称属性,声明中文名称和全名是名称的子类。
1 | @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . |
OWL
上面我们提到,RDFS本质上是RDF词汇的一个扩展。后来人们发现RDFS的表达能力还是相当有限,因此提出了OWL。我们也可以把OWL当做是RDFS的一个扩展,其添加了额外的预定义词汇。OWL,即“Web Ontology Language”,语义网技术栈的核心之一。OWL有两个主要的功能:1. 提供快速、灵活的数据建模能力。2. 高效的自动推理。
1 | @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . |
描述属性特征的词汇
- owl:TransitiveProperty. 表示该属性具有传递性质。例如,我们定义“位于”是具有传递性的属性,若A位于B,B位于C,那么A肯定位于C。
- owl:SymmetricProperty. 表示该属性具有对称性。例如,我们定义“认识”是具有对称性的属性,若A认识B,那么B肯定认识A。
- owl:FunctionalProperty表示该属性取值的唯一性。例如,我们定义“母亲”是具有唯一性的属性,若A的母亲是B,在其他地方我们得知A的母亲是C,那么B和C指的是同一个人。
- owl:inverseOf. 定义某个属性的相反关系。例如,定义“父母”的相反关系是“子女”,若A是B的父母,那么B肯定是A的子女。
本体映射词汇(Ontology Mapping)
- owl:equivalentClass. 表示某个类和另一个类是相同的。
- owl:equivalentProperty. 表示某个属性和另一个属性是相同的。
- owl:sameAs. 表示两个实体是同一个实体。
本体映射主要用在融合多个独立的Ontology(Schema)。举个例子,张三自己构建了一个本体结构,其中定义了Person这样一个类来表示人;李四则在自己构建的本体中定义Human这个类来表示人。当我们融合这两个本体的时候,就可以用到OWL的本体映射词汇。
推理方面的能力:基于本体的推理和基于规则的推理
如果我们用inversOf来表示hasParent和hasChild互为逆关系,上面的数据可以表示为: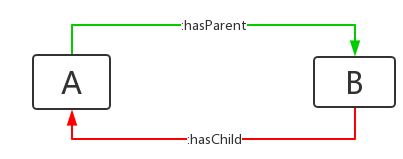 绿色的关系表示是我们RDF数据中真实存在的,红色的关系是推理得到的。
绿色的关系表示是我们RDF数据中真实存在的,红色的关系是推理得到的。
数据准备和实体建模
本实例数据获取方法:以周星驰为初始入口,获取其出演的所有电影;再获取这些电影的所有参演演员;最后获取所有参演演员所出演的全部电影。经过去重处理,我们得到了505个演员的基本信息和4518部电影的基本信息。数据保存在mysql中,其ER图如下: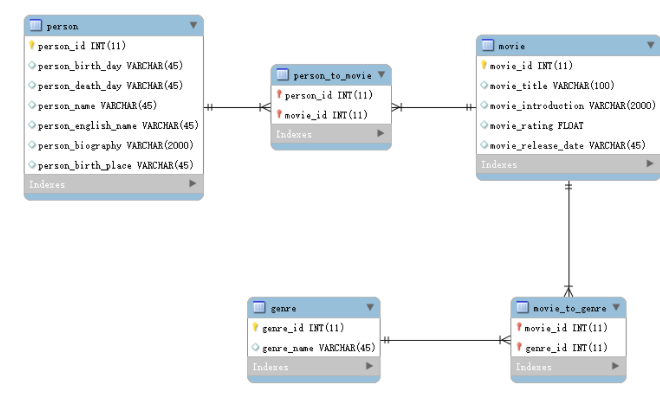
protege字体调大,File-Perference-Renderer-font size即可。
首先填写本体资源的IRI。
然后创建三个类,分别为Genre、Movie、Person
切换到Object Properties,在此建立三个类之间的关系,”hasActedIn”表示某人参演了某电影,因此我们在右下方的3号矩形框中定义该属性的”domain”是人,4号框定义”range”是电影。这个很好理解,”domain”表示该属性是属于哪个类的,”range”表示该属性的取值范围。2号框表示该属性的逆属性是”hasActor”,即,有了推理机,尽管我们的RDF数据只保存了A出演了B,我们在查询的时候也能得到B的演员有A。
最后,我们切换到”Data properties”,我们在该界面创建类的属性,即,数据属性。其定义方法和对象属性类似,除了没有这么丰富的描述属性特性的词汇。其实不难理解,这些描述特性的词汇是传递、对称、反对称、自反等,表明其必定有指向其他资源或自身的边,而我们之前提到过,数据属性相当于树的叶子节点,只有入度,而没有出度。
然后保存成为了owl文件,内容即为之前设置的class、object property、Data property三部分。
关系数据库到RDF
从关系数据库映射到RDF的两个标准
direct mapping
1.数据库的表作为本体中的类(Class)。比如我们在mysql中保存的数据,一共有5张表。那么通过映射后,我们的本体就有5个类了,而不是我们自己定义的三个类。2. 表的列作为属性(Property)。3. 表的行作为实例/资源。4. 表的单元格值为字面量5. 如果单元格所在的列是外键,那么其值为IRI,或者说实体/资源。R2RML
generate-mapping -u root -o kg_demo_movie_mapping.ttl jdbc:mysql:///kg_demo_movie
.\d2r-server lsy.ttl
生成一个mapping的ttl文件,
把每个表映射成为一个类,每一行是一个资源,每一列就是资源的属性。
http://www.pizza.com/ontologies/pizza.owl
Functional Properties:一一映射,一个输入对应的输出是相同的:
比如A的生母是B,也是C,生母关系具有函数性,那么B和C是同一个人。
反函数性可以一对多。
接下来,把默认的映射词汇改为我们本体中的词汇即可。在处理外键的时候要注意当前编辑的属性的domain和range,belongsToClassMap是domain,refersToClassMap是range。
1、三个类中,genre__label和genre_genre_id都去掉了
2、vocab:xxxx 换成了本体构建时候的术语
第一点:我们不需要这两个属性,对我们的系统或者后续应用没有什么帮助。第二点:vocab:xxxx是默认mapping文件定义的转换规则,就是把数据库的字段名和表名直接当成本体。因此要换成我们自己定义的本体。
d2rq:property vocab:person_to_movie; ——> d2rq:property :hasActedIn;
d2rq:property vocab:person_person_birth_place; ——-> d2rq:property :personBirthPlace;
.\dump-rdf.bat -o kg_demo_movie.nt .\kg_demo_movie_mapping.ttl
将数据转为RDF。
这样就利用D2RQ完成了从MySQL数据表到RDF格式数据的转换。
RDF查询语言SPARQL
查询实例:
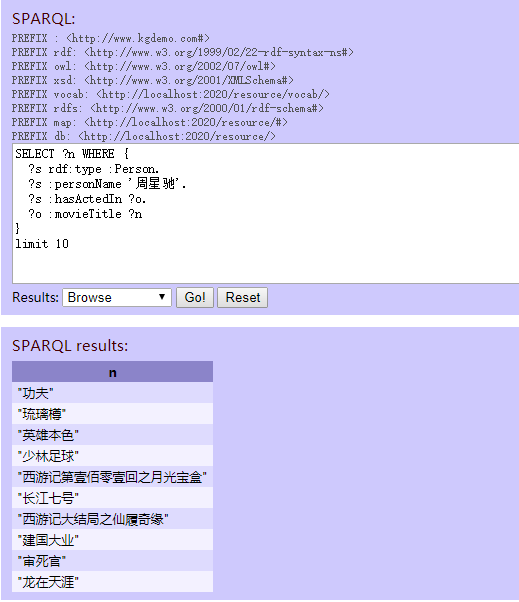
周星驰出演了哪些电影:
PREFIX : http://www.kgdemo.com#
PREFIX rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns#
PREFIX owl: http://www.w3.org/2002/07/owl#
PREFIX xsd:
PREFIX vocab: http://localhost:2020/resource/vocab/
PREFIX rdfs: http://www.w3.org/2000/01/rdf-schema#
PREFIX map: http://localhost:2020/resource/#
PREFIX db: http://localhost:2020/resource/
SELECT ?n WHERE {
?s rdf:type :Person.
?s :personName ‘周星驰’.
?s :hasActedIn ?o.
?o :movieTitle ?n
}
英雄这部电影有哪些演员参演?:
SELECT ?n WHERE {
?s rdf:type :Movie.
?s :movieTitle ‘英雄’.
?a :hasActedIn ?s.
?a :personName ?n
}
D2RQ来实现查询SPRAQL
D2RQ以虚拟的RDF的方式来访问关系数据库中的数据,即我们不需要显式地把数据转为RDF形式。通过默认,或者自己定义的mapping文件,我们可以用查询RDF数据的方式来查询关系数据库中的数据。换个说法,D2RQ把SPARQL查询,按照mapping文件,翻译成SQL语句完成最终的查询,然后把结果返回给用户。
进入d2rq目录,使用下面的命令启动D2R Server:
d2r-server.bat kg_demo_movie_mapping.ttl
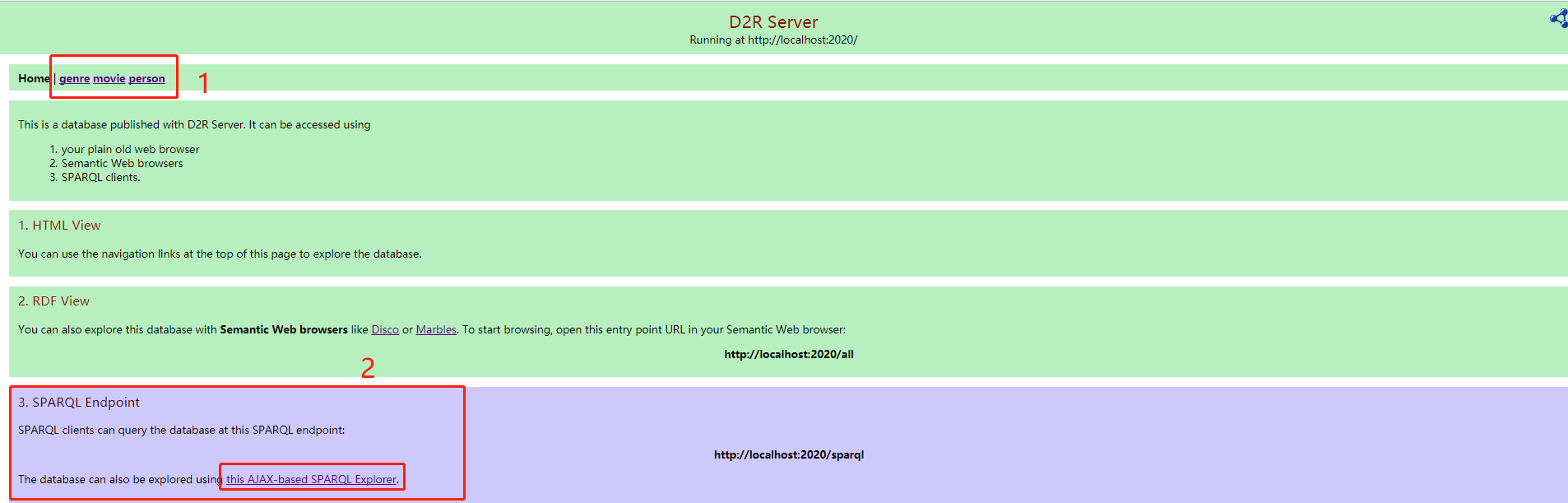
默认端口是2020,在浏览器输入“http://localhost:2020/”,可以看到如下界面:
点击红色方框2中的链接,进入endpoint.
除了利用浏览器,也可以使用python进行交互。见代码中的MyTest文件。
Apache jena SPARQL endpoint及推理
本次实践我们会用到的组件有:TDB、rule reasoner和Fuseki。
- TDB是Jena用于存储RDF的组件,是属于存储层面的技术。在单机情况下,它能够提供非常高的RDF存储性能。目前TDB的最新版本是TDB2,且与TDB1不兼容。
- Jena提供了RDFS、OWL和通用规则推理机。其实Jena的RDFS和OWL推理机也是通过Jena自身的通用规则推理机实现的
- Fuseki是Jena提供的SPARQL服务器,也就是SPARQL endpoint。其提供了四种运行模式:单机运行、作为系统的一个服务运行、作为web应用运行或者作为一个嵌入式服务器运行。
创建一个目录(我这里命名为“tdb”)用于存放tdb数据。进入“apache-jena-X.X.X”文件夹的bat目录,可以看到很多批处理文件,我们使用“tdbloader.bat”将之前我们的RDF数据以TDB的方式存储。命令如下:
.\tdbloader.bat —loc=”D:\apache jena\tdb” “D:\d2rq\kg_demo_movie.nt”
“—loc”指定tdb存储的位置,即刚才我们创建的文件夹;第二个参数是由Mysql数据转换得到的RDF数据。
进入入“apache-jena-fuseki-X.X.X”文件夹,运行“fuseki-server.bat”,然后退出。程序会为我们在当前目录自动创建“run”文件夹。将我们的本体文件“ontology.owl”移动到“run”文件夹下的“databases”文件夹中,并将“owl”后缀名改为“ttl”。在“run”文件夹下的“configuration”中,我们创建名为“fuseki_conf.ttl”的文本文件(取名没有要求),加入如下内容:
报错的话,进入到D:\MMKG\env\apache-jena-3.5.0\tdb目录下,将前缀为prefix的文件全部删除,再次运行即可。
再次运行“fuseki-server.bat”,如果出现如下界面表示运行成功:
进入localhost:3030
PREFIX : http://www.kgdemo.com#
PREFIX rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns#
PREFIX rdfs: http://www.w3.org/2000/01/rdf-schema#
SELECT * WHERE {
?x :movieTitle ‘功夫’.
?x ?p ?o.
}
进行如下查询,可以得到hasActor属性,电影的“hasActor”属性是通过OWL推理机得到的,即我们原本的RDF数据里面是没有的。
在“databases”文件夹下新建一个文本文件“rules.ttl”,填入如下内容:1
2
3
4
5
6
7
8@prefix : <http://www.kgdemo.com#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix xsd: <XML Schema> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
[ruleComedian: (?p :hasActedIn ?m) (?m :hasGenre ?g) (?g :genreName '喜剧') -> (?p rdf:type :Comedian)]
[ruleInverse: (?p :hasActedIn ?m) -> (?m :hasActor ?p)]
我们定义了一个名为“ruleComedian”的规则,它的意思是:如果有一个演员,出演了一部喜剧电影,那么他就是一位喜剧演员。修改配置文件“fuseki_conf.ttl”:
demo实例
基本流程
此demo是利用正则表达式来做语义解析。我们需要第三方库来完成初步的自然语言处理(分词、实体识别),然后利用支持词级别正则匹配的库来完成后续的语义匹配。
分词和实体识别(人名和电影名)我们用jieba来完成。jieba是一个轻量级的中文分词工具,有多种语言的实现版本。对于分词,在实验环境中,jieba还是勉强能用。在我们这个demo当中,有些经常会被使用的词语并不能被正确切分。比如:“喜剧电影”、“恐怖电影”、“科幻电影”、“喜剧演员”、“出生日期”等,在分词的时候,jieba把它们当作一个词来处理,我们需要手动调整词语的频率使得“喜剧电影”能被切分为“喜剧”和“电影”。至于实体识别,jieba对于人名的识别精度尚可接受,但是电影名称的识别精度太低以至于完全不可用。因此,我们直接把数据库中的人名和电影名导出,作为外部词典;使用jieba的时候加载外部词典,这样就能解决实体识别的问题。
将自然语言转为以词为基础的基本单位后,我们使用REfO(Regular Expressions for Objects)来完成语义匹配。具体实现请参考OpenKG的demo或者本demo的代码。
匹配成功后,得到其对应的我们预先编写的SPARQL模板,再向Fuseki服务器发送查询,最后将结果打印出来。
- “crawler”文件夹包含的是我们从”The Movie DB”获取数据的脚本。
- “KB_query”文件夹包含的是完成整个问答demo流程所需要的脚本。
- “external_dict”包含的是人名和电影名两个外部词典。csv文件是从mysql-workbench导出的,按照jieba外部词典的格式,我们将csv转为对应的txt。
- “word_tagging”,定义Word类的结构(即我们在REfO中使用的对象);定义”Tagger”类来初始化词典,并实现自然语言到Word对象的方法。
- “jena_sparql_endpoint”,用于完成与Fuseki的交互。
- “question2sparql”,将自然语言转为对应的SPARQL查询。
- “question_temp”,定义SPARQL模板和匹配规则。
“query_main”,main函数。在运行”query_main”之前,读者需要启动Fuseki服务,具体方法请参考上一篇文章。
streamlit run streamlit_app.py —server.enableCORS=true
终端输入可在浏览器中使用。